

Collateral data model
With today’s cost pressures combined with modest revenue opportunities, all firms must design target collateral infrastructure to be highly cost-efficient enabled by straight through processing. Poor data quality has long been known to be a major barrier to STP. As cleared volumes are set to rise dramatically, firms without a high quality data strategy face increasing numbers of exceptions, margin disputes, operational cost and risk.
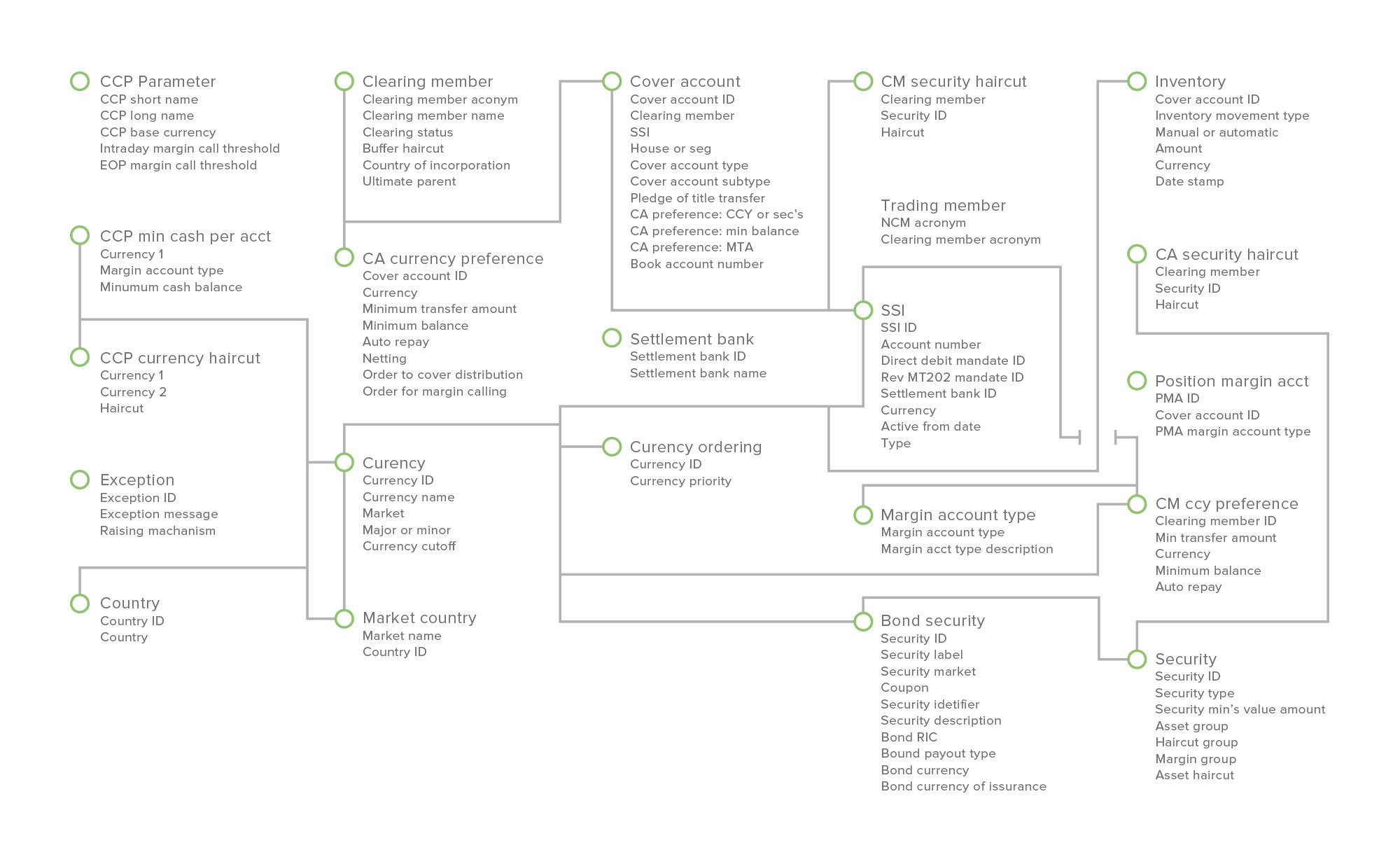
An sample data model
Many data types are involved: reference data such as LEI, product data, netting sets, book structures, counterparty data and SSIs; trade data such as trade IDs, netting sets, risk factors and sensitivities; collateral data including eligibility schedules and haircuts; and market data. Use of existing investments such as trade repository infrastructure should be considered for golden sources.
Our approach covers:
- logical data model – a system-independent schedule of data entities, relationships and key attributes created or used in the end-to-end clearing and collateral management process
- business glossary – an agreed set of consistent business definitions for data entities and attributes to improve understanding and communication between business and technology
- physical data model – identifying which system each entity and attribute exist in, enabling identification and specification of system interfaces needed to maximise collateral STP
TFE accelerates design of the clearing and collateral data model, reducing project time, effort and risk, through our business knowledge of clearing and collateral, our data model templates, and our data modelling skills.
If you think TFE could help your business please get in touch
